Welcome Back
This week is all about demographics, so lets talk about it!
When pollsters review data to make predictions, they have a lot of factors to consider. I have covered some of these in prior posts, including economic factors, public opinion polls, and historical trends. Today, I will explore trends that are impacted–or are not–by demographics. The primary demographics included in today’s data are race, gender, education level, income, religion, and a few others!
For the first regression of the way (woot woot we love regressions) take a look down below. This regression tells us which demographic factors have been historically most accurate, and which demonstrated less accurate results.
Interestingly, this form shows that age is not statistically significant in which party a candidate votes for. I say this is interesting because the Harvard Kennedy School Institute of Politics Spring 2024 Poll demonstrated that likely young voters were much more likely to vote for the Democrat (Biden) compared to the Republican (Trump). For voters under 30, Biden had the lead of 8 percentage points, which seemingly demonstrates something different than this– interesting![1]
Additionally, I see that gender and race are in fact quite demonstrative of voting patterns, with negative coefficients of -0.429 and -0.548 respectively. According to the Pew Research Center, data shows that black voters turnout less than white voters, but overwhelmingly vote for Democrats, with roughly 93% of black voters voting for Democrats in the 2022 midterm elections![2]
##
## Logistic Regression Results
## =============================================
## Dependent variable:
## ---------------------------
## pres_vote
## ---------------------------------------------
## age 0.001
## (0.003)
##
## gender -0.429***
## (0.093)
##
## race -0.548***
## (0.061)
##
## educ -0.340***
## (0.061)
##
## income 0.049
## (0.047)
##
## religion -0.215***
## (0.042)
##
## attend_church -0.211***
## (0.033)
##
## southern -0.410***
## (0.105)
##
## region
##
##
## work_status 0.096**
## (0.046)
##
## homeowner -0.177**
## (0.082)
##
## married -0.072***
## (0.028)
##
## Constant 4.358***
## (0.437)
##
## ---------------------------------------------
## Observations 2,088
## Log Likelihood -1,282.131
## Akaike Inf. Crit. 2,588.262
## =============================================
## Note: *p<0.1; **p<0.05; ***p<0.01
Moving On :)
Next, take a look at this in-sample accuracy analysis, which will help us understand how succesful the regression model is in predicting the vote outcome!
You will see first that the True Positives (positive meaning Democrat) came to 746, while True Negative (Republican) is 660. False positives (meaning they incorrectly guessed Republican) is 336, and the False negative is 346. These equate to a accuracy of 67.34%…which to me doesn’t sound great. If we can only predict the outcome of the election correctly 67% of the time, what are we even here for!? (just kidding on the last part of course!) This model is useful, but not perfect!
You will see an out of sample response below, and spoiler alert, it is not much different!
## Confusion Matrix and Statistics
##
## Reference
## Prediction Democrat Republican
## Democrat 746 336
## Republican 346 660
##
## Accuracy : 0.6734
## 95% CI : (0.6528, 0.6935)
## No Information Rate : 0.523
## P-Value [Acc > NIR] : <2e-16
##
## Kappa : 0.3456
##
## Mcnemar's Test P-Value : 0.7304
##
## Sensitivity : 0.6832
## Specificity : 0.6627
## Pos Pred Value : 0.6895
## Neg Pred Value : 0.6561
## Prevalence : 0.5230
## Detection Rate : 0.3573
## Detection Prevalence : 0.5182
## Balanced Accuracy : 0.6729
##
## 'Positive' Class : Democrat
##
## Confusion Matrix and Statistics
##
## Reference
## Prediction Democrat Republican
## Democrat 184 80
## Republican 88 169
##
## Accuracy : 0.6775
## 95% CI : (0.6355, 0.7175)
## No Information Rate : 0.5221
## P-Value [Acc > NIR] : 4.301e-13
##
## Kappa : 0.3547
##
## Mcnemar's Test P-Value : 0.5892
##
## Sensitivity : 0.6765
## Specificity : 0.6787
## Pos Pred Value : 0.6970
## Neg Pred Value : 0.6576
## Prevalence : 0.5221
## Detection Rate : 0.3532
## Detection Prevalence : 0.5067
## Balanced Accuracy : 0.6776
##
## 'Positive' Class : Democrat
##
Other Avenues
So, what about random forest? How accurate are random forest models in this projection? Take a look! Also, in case you were wondering, the Random Forest model is an ensemble learning tool that constructs decision trees, and then when it runs regressions or classifications it outputs the results of individual trees! Random forests are fun-and good for the environment (actually probably not considering the power used to run my computer, and the server, and github…but then again, this is a gov class, not a ESPP one!)
In the random forest model you can see that the accuracy comes out to just above 70%, meaning it is the most accurate so far!
## Confusion Matrix and Statistics
##
## Reference
## Prediction Democrat Republican
## Democrat 774 302
## Republican 318 694
##
## Accuracy : 0.7031
## 95% CI : (0.683, 0.7226)
## No Information Rate : 0.523
## P-Value [Acc > NIR] : <2e-16
##
## Kappa : 0.4053
##
## Mcnemar's Test P-Value : 0.5469
##
## Sensitivity : 0.7088
## Specificity : 0.6968
## Pos Pred Value : 0.7193
## Neg Pred Value : 0.6858
## Prevalence : 0.5230
## Detection Rate : 0.3707
## Detection Prevalence : 0.5153
## Balanced Accuracy : 0.7028
##
## 'Positive' Class : Democrat
##
What does data look like?
I often look at sites like 538 or CNN to view election projections and wonder what their data is, and where it comes from. There is so much available information in the world, not even including the data behind paywalls or copyrights. Just as an example, I have attached a tidbit of Massachusetts voter file information, which includes variables of age, age range, and gender, as well as if the voter is deceased or not.
As a Massachusetts resident, perhaps you could find my information in this data set, but I can confidently say that this small preview does not include me–considering there are no gender and age matches for me!
Now, scroll on to see what I do with this data!
## # A tibble: 10 × 5
## sii_state sii_deceased sii_age sii_age_range sii_gender
## <chr> <dbl> <dbl> <chr> <chr>
## 1 MA 0 47 C F
## 2 MA 0 80 F M
## 3 MA 0 71 E M
## 4 MA 0 NA <NA> F
## 5 MA 0 54 D M
## 6 MA 0 63 D M
## 7 MA 0 30 B F
## 8 MA 0 45 C M
## 9 MA 0 32 B M
## 10 MA 0 24 A M
Simulation Time!
This week in lab, we learned how simulations work–and how sometimes maybe they don’t work. Luckily, this one seems to work. After taking a little while to run on my computer (10,000 simulations!!), we have results to examine!
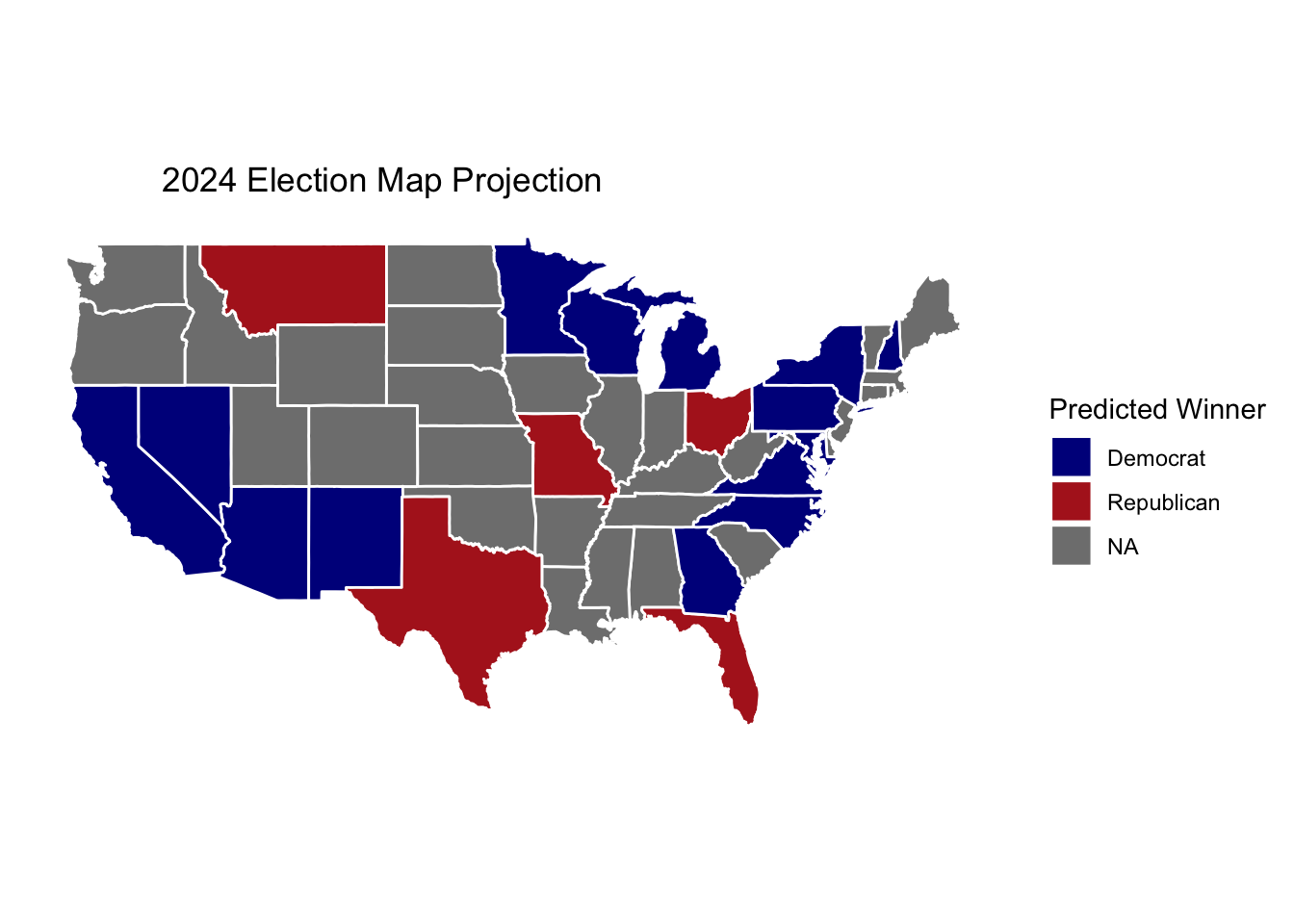
After all that fun wrangling, you will see results below!
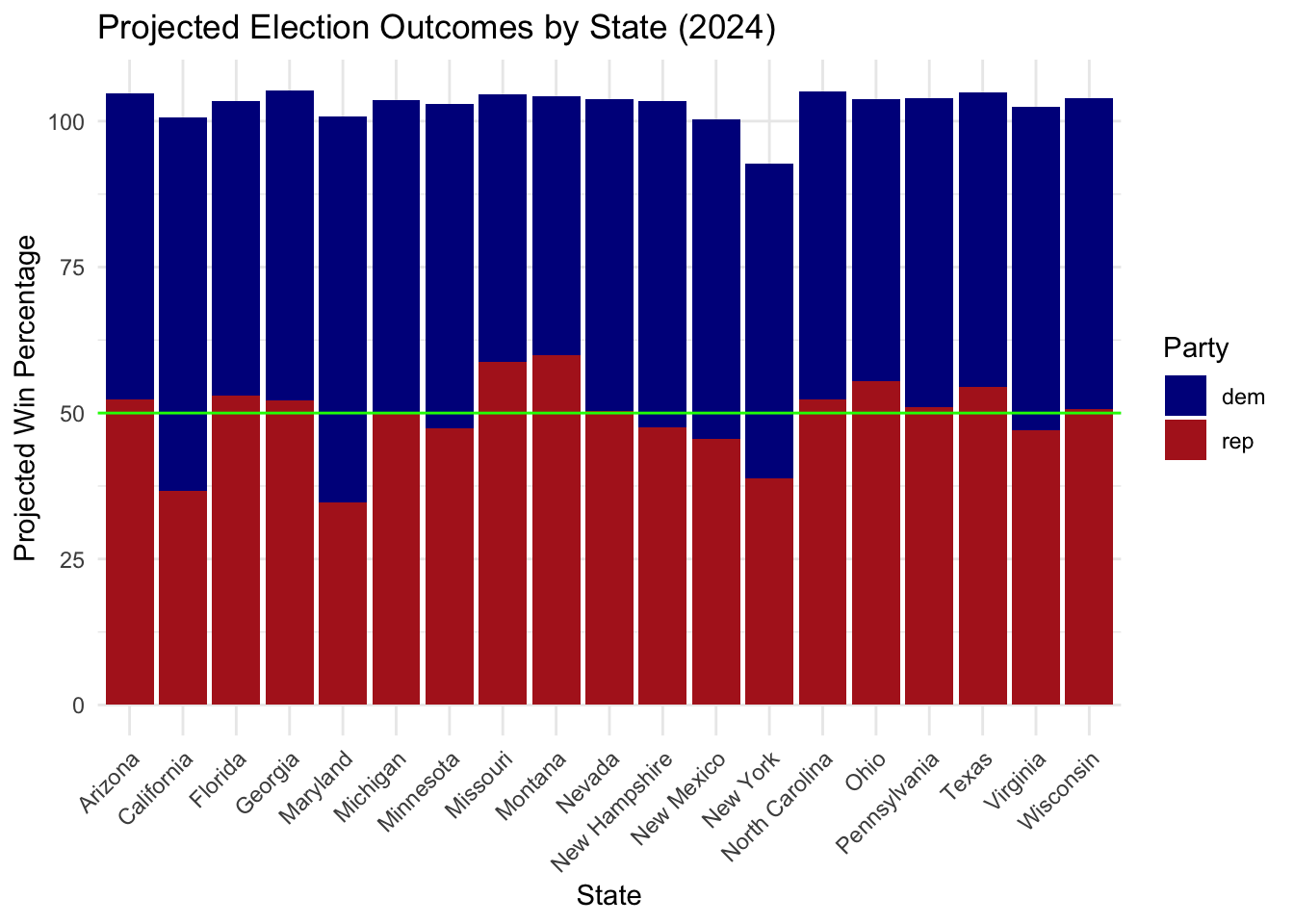
Citations [1] - https://iop.harvard.edu/youth-poll/47th-edition-spring-2024
[2] - https://www.pewresearch.org/politics/2023/07/12/voting-patterns-in-the-2022-elections/
[] - as always, code borrowed from Teaching Fellow Matthew Dardet, check him out here - https://www.matthewdardet.com